win32com のコーディングを pandas に書き換えた
ノート PC では
オフィスツールに WPS Office2 を使っているんだけど
最近、win32com を使った Python プログラムを実行したら
次のエラーがでて実行されない。

どうも win32com は Excel の実行ファイルがないと
実行できないようだ。
仕方がないので
openpyxl で処理を書き直そうと思ったが
元々 openpyxl より win32com のほうが
Excel の操作はやりやすそうなので
win32com でコーディングしていたから
openpyxl ではできないこともある。
コーディングして
実行してみたら
なぜかソートでエラーになる。

ソートして別のシートに振り分けるのが
目的のプログラムなので
ソートできないとまったく意味がない。
ソートを手書きでコーディングするのも
面倒だし非効率だろう。
どうしようと思って
ほかのライブラリを探したが
XlsxWriter や xlwings も Excel の実行ファイルがないと動かない。
なのでデータ処理自体は問題なくこなせると思われる
pandas を使うことにした。
書式や体裁はあとで手動で変更するしかないだろう。
pandas でコーディングしたら
いままで win32com や openpyxl で
何十行もコーディングしていた処理を
1 行で記述することができた。
# 重複行を削除
1 行なのでデバッグする必要もない。
# セグメント番号順でソート
df1 = df1.sort_values(by='col4')
ソートや重複行の削除、ほかのシートへのデータの移動など
どの操作もほとんど 1 行で記述できるので
プログラムが非常に短くなった。
ある条件でデータを別のシートに移動する場合は
ソートする必要もない。
条件を指定して新しいデータフレームを作ればいいだけだ。
ほとんど pandas が内部で処理するので
デバッグも最後のデータを確認すればいい程度だ。
編集したデータは pandas のExcelWriter を使用して
Excel ファイルに出力できる。
これでとりあえずデータを使える状態になった。
でも、ExcelWriter で出力した内容は
本当にデータだけで
体裁を変えて見やすくするのに
手間がかかる。
なので pandas で出力された Excel ファイルを
openpyxl で読み込んで
体裁を変えようと思ったが
なぜか読み込みでエラーになる。

シートを開くところでシートがないと言われてしまう。
シート名をリストしたら空だった。
WPS Spreadsheets で開くと
普通に開けてシートもある。
ちょっと原因がわからないので
ほかの方法を考えた。
pandas に styleframe というライブラリを組み合わせると
ある程度 Excel ファイルの体裁を整えることができるようだ。
from styleframe import StyleFrame, Styler, utils
w_style1 = Styler(horizontal_alignment=utils.horizontal_alignments.left, \
vertical_alignment=utils.vertical_alignments.top, wrap_text=True, \
font=utils.fonts.arial, font_size=11.0, border_type=utils.borders.hair)
with StyleFrame.ExcelWriter(wb_name) as writer:
sf1 = StyleFrame(df1)
sf1.set_column_width(columns=['col1', 'col2'], width=53.55)
sf1.apply_column_style(cols_to_style=['col1', 'col2'], styler_obj=w_style1)
調べながらコーディングしたら
列の幅、上揃え、左揃え、テキストの折り返し、フォント、フォントサイズ、
境界の線、数値形式の指定を設定することが出来た。
シートを 115% に拡大したいがたぶん機能がないと思う。
あとフォントを MS P ゴシックに変えたいが
arial や calibri などしかない。
styleframe のドキュメントページを見ると
aegean から ellinia までの 11 個しか
フォントがなくて
アルファベット順のようなので
F 以降のフォントが欠けているんじゃないかと思うが
ドキュメントページがそれなので
ほかに情報はなかった。
まあそれでも元の処理のほとんどは再現できたのでよかった。
これからは Excel ファイルの操作は
pandas と styleframe でやろうと思う。
このプログラムをしばらく使ったら
前処理のデータ数より pandas のデータ数が
必ず 1 件少なくて
なんでだろうなと思ったら
pandas の read_excel() では
デフォルトで 1 行目をヘッダーと見なすようで
1 行目が除外されていたようだ。
1 行目もデータとして認識させるには
read_excel() に header=None を指定すればいいだけだ。
Kingsoft の WPS Spreadsheets に配色パターンを追加した
来年の 10 月で Office 2019 がサポート終了になるので
Kingsoft の WPS Office 2 を最近購入して(3600 円)
主に WPS Spreadsheets を試しに使っている。
Microsoft Office の機能の 70% がカバーされているそうで
わたしの用途では特に問題なさそうだ。
セルの関数を多少使う程度なので。
マウスのホイールで 1 画面ずつスクロールできないのは
ちょっと不便だ。
キーボードの Pgup、Pgdn を押すか
スクロールバーをマウスでクリックすれば
1 画面ずつスクロールできるが。
あと、ファイルを更新して保存しても
なぜか Explorer で更新日時が更新されないことがよくある。
リフレッシュすると反映される。
VBA は使えないのかな?
きょう、気が付いたが
WPS Spreadsheets では配色パターンを追加できないようだ。
Microsoft Excel では配色パターンを自分で設定して保存できる。

わたしは Excel 2003 のデフォルト?の配色パターンが好きで
それを保存してずっと使っている。
でも、WPS Spreadsheets では追加する機能はない。
既定で用意されている配色パターンもあまりいい色ではない。
Python での配色パターンの設定方法を探していて
マクロに記録してみたら
ActiveWorkbook.Theme.ThemeColorScheme.Load ( _
"C:\Users\[username]\AppData\Roaming\Microsoft\Templates\Document
Themes\Theme Colors\Office 2003.xml" )
と記録された。
わたしが保存した配色パターンはこの場所にあるようだ。
それをコピーして
WPS Office 2 の以下のテーマカラーのディレクトリに貼り付けてみた。
C:\Program Files (x86)\Kingsoft\WPS Office\11.2.0.10624\office6\document theme\theme colors
WPS Spreadsheets を起動し直して
レイアウトの色を見たら
Office 2003 の設定が表示された。
あっさり配色パターンを追加できた。
きょう、気が付いたもう一つの問題は
文字列が入力されているセルをコピーして
CAT ツールの検索ペインに貼り付けたときに
先頭にスペースが 5 個くらい入ってしまうことだ。
それを削除しないと検索できない。
見直しの作業にかなり影響する。
問題ないファイルも多いので
そのファイル独自の問題かもしれない。
これはもう少し様子を見ようと思う。
(その CAT ツールだけの問題のようだ)
ランダムハウス英語辞典のデータを EPWING 形式に変換した
最近新しいノート PC を買って
EPWING の辞書を新しいノート PC にコピーしたんだけど
ランダムハウス英語辞典だけは
インストール先を参照する形になっていて
新しいノート PC には DVD ドライブがないので
とりあえず、インストールディレクトリをコピーしたが
検索はされるんだけど
見出しの単語の表示が化けてしまう。
なぜかはわからない。
Windows 10 ではまったく問題なかったが
Windows 11 は何かが違うのか?
仕方がないので
ランダムハウス英語辞典のインストール CD を
USB メモリーにコピーしてインストールしようとしたが
なぜか setup.exe のようなものが見当たらない。
どうやってインストールしたのかももう覚えていない。
でも、辞書データ自体は
インストール CD とインストール先で同じようなので
インストールしても同じだろう。
ランダムハウス英語辞典は
わたしのメインの辞書なので
これが使えないと困ってしまう。
新しいやつを買わないといけないのかと思って
ネットで探してみたが
2002 年にリリースされた
バージョン 2.0 が最新のようだ。
しかも 5 万円くらいする。
わたしが持っているのは
バージョン 1.1b だ。
これは本当に困ったので
いまあるデータを変換できないかと思って
ネットで調べたら
ランダムハウス英語辞典 Toolkit というのがあった。
でも、説明が細かくて
ちょっと大変だなと思ったら
簡単に書いているページがあった。
この手順をそのとおりに実行したら

最初、srd.ebs ファイルが作成されなかったが
ログを見たら
readme.txt ファイルが見つからないと書いてあったので
DATA ディレクトリにコピーしたら
srd.ebs ファイルが作成された。

そのファイルを EBStudio で指定して実行したら
EPWING 形式のファイルが作成された。

これでランダムハウス英語辞典を
新しいノート PC で使用できる。
win32com で Outlook の受信トレイのメールを読み込む(Python)
Python でメールを操作する練習をしようと思って
ちょっと調べたら
メールサーバーに直接アクセスする方法もあるが
win32com で Outlook を操作できるようなので
とりあえずそれでいじってみた。
メールの送信は誰かが書いたコードをコピペするだけでできたが
メールの受信は
inbox = mapi.GetDefaultFolder(6)
のようなコードが使われているが
わたしの環境では読み取れない。
folders = inbox.Folders
for folder in folders:
print('Name: ' + folder.name)
というコードを付加してフォルダーを表示してみると
Name: 連絡先候補
Name: スレッド アクション設定
Name: クイック操作設定
と表示される。
読み取りたいフォルダー番号はおそらく 5 なんだけど
フォルダー名を指定してもうまく読み取れない。
なので、ネットで調べたら
英語のページに
別の方法があったので
それでコーディングしてみた。
import win32com.client
# APPの初期化
for mail in inbox_mails.Items:
print('SenderEmailAddress: ', mail.SenderEmailAddress)
print('SenderName: ', mail.Sender)
print('Subject: ', mail.subject)
print('To: ', mail.To)
print('Cc: ', mail.Cc)
print('ReceivedTime: ', str(mail.receivedtime))
print('Body: ', mail.body)
print('Attachments: ', mail.Attachments)
このコードで読み取ることができた。
わたしは Outlook に
プロバイダーのメール、Hotmail、Yahoo メールなどを複数登録してあるので
メールアドレスが最初のフォルダー名となっているようだ。
とりあえず、Outlook のメールを受信できるようになったが
やりたいのは受信したメールに返信することで
受信内容を編集すればできないことはないが
何か簡単な方法はないかなといま思案している。
Python で win32com を使って Excel の重複行を削除する
前に作った .mxliff ファイルを Excel ファイルに出力するプログラムで
同じ内容のセグメントが複数出力されていたので
何度も同じ文を見直さなくてはいけなくて
これは重複する行を削除しないと
効率が悪いなと思って
プログラムに機能追加することにした。
Excel で .xlsx ファイルを開くと
[データ] > [重複の削除] というメニューがあって
そこで重複行を削除できるようだ。

Excel 自体にその機能があるんだから
win32com でもあるんじゃないかなと思って
とりあえず、Excel でその操作をマクロに記録してみた。
ActiveSheet.Range("$A$1:$F$1000").RemoveDuplicates Columns:=Array(1, 2), _
Header:=xlNo
RemoveDuplicates というのが win32com にあれば
それを使うことができるが
ネットで検索してもあまりヒットしない。
「Python で Excel の重複行を削除する」と検索すると
Excel ファイルを pandas で読み込んで
drop_duplicates で削除して
Excel ファイルに書き戻すという記事があって
それだと確実にできそうだが
pandas に全部読み込んで Excel ファイルに書き戻すというのが
ちょっと無駄な感じがしたので
win32com のほうをコーディングしてみた。
ws.Range("A:F").RemoveDuplicates Columns:=Array(1, 2), Header:=xlNo
実行すると Columns でエラーになる。
この書き方は Python じゃないな。
かっこで囲んでみた。
ws.Range("A:F").RemoveDuplicates(Columns:=Array(1, 2), Header:=xlNo)
Columns は通ったが
今度は Array でエラーになる。
単純に取ってしまえばいいかなと思って
ws.Range("A:F").RemoveDuplicates(Columns:=(1, 2), Header:=xlNo)
としたら正常に実行されてしまった。
xlno はすでに定義してあった(値は 2 で、範囲全体を対象とする)。
わりとあっさりできてしまった。
これで重複した行を何度もチェックする必要がなくなった。
ソースとターゲットの両方で重複を確認しているので
同じ文を違う訳し方にしているところは維持される。
Python で .mxliff ファイルを Excel ファイルに出力するプログラムを作った
翻訳ツールで作業していて
一通り翻訳した後に見直すとき
テキストファイルや Excel ファイルに出力して
それでチェックしている。
Memsource で作業しているときは
ローカルに .mxliff ファイルが作成される。
.mxliff ファイルは
Memsource XML Localization Interchange File Format の略で
XML または XLIFF の一種だ。
テキストエディターで開いたり
プログラムで編集することができる。
Xbench 3.0(有料版)だと .mxliff ファイルを読み込むことができるんだけど
Xbench 2.9(無料版)だと読み込むことができない。
それについては調べて
.mxliff ファイル内のすべての <target> タグに
state='translated' を追加して
<target state='translated'> のようにすれば
読み込まれることはわかったんだけど
line = line.replace("<target>","<target state='translated'>")
Xbench 2.9 だとテキストファイルに出力したときに
マッチ率が出力されない(Xbench 3.0 は出力されたと思う)。
それだと作業しづらいので
Python で .mxliff ファイルの内容を
Excel ファイルに出力するプログラムを作成することにした。
入力が .mxliff ファイルで出力が Excel ファイル
使用するライブラリは openpyxl、win32com、BeautifulSoup など。
from bs4 import BeautifulSoup
import openpyxl
import win32com.client
最初に 2 つのファイルをオープンして
BeautifulSoup で
各セグメントの内容がある <group> タグを検索してループし
<source> と <target>、<context fuzzyMatch>(マッチ率)を
Excel ファイルに出力する。
<trans-unit m:locked> が True のセグメントは
翻訳対象外のセグメントなのでスキップする。
これで .mxliff ファイルの内容が Excel ファイルに出力される。
これで翻訳作業に使うことができるんだけど
せっかくここまでプログラムを作ったので
普段 Excel で見直し用にデータを編集していた作業を
プログラムでやってしまうことにした。
まず、新規の翻訳とファジーマッチを別々のシートに分ける。
要注意として翻訳中にマーキングしておいたセグメントを
ソートしてシートの一番上に持ってくる。
各行の幅の調整やセルの上揃え、セルの折り返し、ソート、シートの倍率などを設定する。
xlTop = -4160
ws.Range("A:G").VerticalAlignment = xlTop
いつも Excel では自分で定義した Office 2003 の配色を使っているんだけど
([ページ レイアウト] > [配色] > [ユーザー定義])
それだけは Python で設定する方法がわからなかった。
これをしばらく使ってみて
レアケースのバグが何回かでたが
問題なく使用できている。
openpyxl と win32com を前半と後半でそれぞれ使っているからか
Excel ファイルを受け渡すときに File not found のエラーがでるときがある。
それは Windows でサインインしなおすと解消される。
(開いている Excel を全部閉じるとエラーは起こらないようだ)
必要に迫られて Python のプログラムを作ったんだけど
逆に作業を効率化できた。
<target> タグを <target state='translated'></target> に
変更するだけのプログラムも作ったので
Xbench でチェックすることもできる。
英辞郎第七版を PDIC 形式から EPWING 形式に変換してみた
先週、ブックオフに行ったら
英辞郎第七版が 200 円で売っていたので
EPWING 辞書として使えるかなと思って買ってみた。

うちに帰ってきてから調べたら
217 万項目収録で 3080 円。
英辞郎第七版は 190 万項目収録で 200 円だったので
十分使用価値があってお得だと思う。
EPWING のツールではそのまま使用できないそうだ。
でも、EBStudio というツールを使うと
とりあえず、英辞郎を普通にインストールしてみようと思って
インストーラーを起動した([管理者として実行] から実行)。

[INSTALL] を選択するとインストールが始まる。

以前のバージョンがある場合の注意の画面がでて
[次へ] をクリックしたら
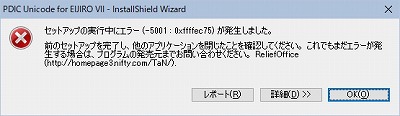
エラーで止まってしまった。
アルクのホームページなどを調べて
いろいろ試したが解決しない。
200 円が無駄になったかと思ったが
専用ツールのインストールはあきらめて
インストール CD に辞書データのテキストファイルがあったはずなので
CD を見てみたら
Eijiro7T というフォルダーに TXT.zip というファイルがあった。
開いてみると

Eiji-136.txt など 4 ファイルが入っていた。
英和辞書だけ欲しいので
Eiji-136.txt を解凍した。
さて、このファイルを変換しないといけないので
EBStudio をダウンロードしてインストールした。
現在のバージョンは EBStudio2 だ。
起動すると
次のような画面が表示される。

マニュアルを読んだが
操作方法がよくわからないので
とりあえず、英辞郎のテキストファイルを
ドラッグアンドドロップしてみた。

いくつか設定画面がでて
適当に進めたら
ファイルが登録された。
あとは変換の設定を指定する必要がある。
マニュアルによると
英辞郎用の設定ファイルがあるそうなので
EBStudio2 を起動し直して
EBStudio2 の zip ファイルを解凍したフォルダーの
support\jiro-eijieo.ebx を EBStudio2 に
ドラッグアンドドロップしたら

英辞郎用に設定されたようだ。
次に、英辞郎のテキストファイルをドラッグアンドドロップしたら

この設定画面(2/2)が表示されたので
[辞郎形式] を選択して [OK] を押した。
(最初は [PDICテキスト形式] や [Plain Text] を選択してしまって
辞書ファイルは作成されて DDwin で認識されたが
単語が表示されなくて途方に暮れたが)
これで設定が完了したようなので
[EPWING] > [変換] を選択して変換を実行した。

10 秒ほどで完了した(マシンは Core i3)。
[出力パス] に指定したフォルダーに
辞書ファイルが作成されていた。
これをほかの辞書ファイルを格納しているフォルダーにコピーして
DDwin で辞書検索したら
英辞郎の辞書が検出されてグループに登録できた。
(辞書の登録時は [管理者として実行] から起動する必要があるようだ)

無事に DDwin で英辞郎の単語が検索されるようになった。
項目数が多すぎるので
ちょっと邪魔なくらいだ。
一番下に表示されるようにした。
いままでは
手持ちの辞書でいい訳語が見つからないときだけ
ネットの英辞郎で検索していたが
これからは DDwin で一緒に検索されるようになったので
便利になった。
その後、このブログを書くために
試しに進めてみたら
なぜかエラーがでずに進めることができた。
なぜ動作が変わったのかわからない。

まあでも専用ツールも使用できるようになった。
たぶん、DDwin しか使わないと思うが。
辞書を増やすことができて
お買い得だった。